genc4: визуализация архитектуры
В прошлой заметке про архитектурный резпозиторий мы говорили о том, как хранить и актуализировать документацию. Логичным продолжением стал вопрос о тулинге, который мог бы автоматизировать две ключевые задачи:
- Построение карты сервисов на основе метаданных appkit
- Визуализацию межсервисного взаимодействия через HTTP, также на основе appkit
Это отличный повод попробовать навайбкодить этот тулинг, а заодно проверить гипотезу: нужно ли уметь программировать при вайбкодинге или нет?
Дисклеймер: к вайбкодингу и нестабильной генерации кода я отношусь крайне скептически.
Какую задачу решаем
Цель — получить актуальную карту взаимодействия микросервисов в пару кликов:
- Запускаем утилиту, она собирает метрики и строит TOML-файл с топологией.
- Создаем файл с настройками визуализации (максимально простой) и генерируем из двух файлов диаграмму в нотации C4 через PlantUML.
Ключевая идея: C4-диаграмма — это не источник истины, а способ визуализации. Источник истины — файл с топологией, который собирается автоматически с окружения через метрики.
Полученные артефакты (TOML + диаграммы) можно и нужно положить в архитектурный репозиторий. А дальше — настроить периодическую задачу в CI для их автоматической актуализации.
Почему именно из метрик?
Откуда обычно берут «паспорт сервиса»? Варианты:
- Файл в репозитории (машиночитаемый, но ручной).
- Отдельный реестр сервисов (требует поддержки).
- Система трейсинга (сложность внедрения и анализа).
Метрики выигрывают по простоте внедрения, актуальности данных и низкой стоимости поддержки.
Почему это сработает?
- В каждом сервисе есть метадата, в которой описано, что это за сервис и с кем взаимодействует.
- Межсервисное взаимодействие просиходит через HTTP (JSON-RPC 2.0).
- Все клиенты сгенерированы с помощью rpcgen, в котором используется HTTP клиент с метриками через vmkteam/appkit.
- Асинхронное взаимодействие просиходит через brokersrv (nats jetstream + zenrpc), поэтому прямо из метрик HTTP клиента можно определить тип связи (синхронный или асинхронный).
- Метадата статична (и может расходиться с актуальной картиной).
Все эти факты говорят нам о том, что данные для решения задачи есть.
Что еще можно получить из метрик при стандартизированном стеке?
В метадате есть 4 ключевых флага:
Public API— есть публичное API.Private API— есть приватное API.Brokersrv Queue— принимает сообщения через brokersrv (NATS JetStream).Cron— есть периодические задачи.
Примечательно, что cron во всех сервисах реализован через vmkteam/cron, где из коробки есть метрики. Запомним это.
Что навайбкодилось?
- За 60% Weekly лимитов в Claude Code Pro с Opus 4.5 получился проект genc4, который решает поставленные задачи, и даже больше.
- Программа была полностью сделана роботом под управлением человека.
- У проекта достаточно обширный README.md, где полностью описана вся функциональность.
Пример
Файл с топологией: креатив от LLM. Посмотреть на результаты можно в testdata
А вот визуальный результат — сгенерированная диаграмма:
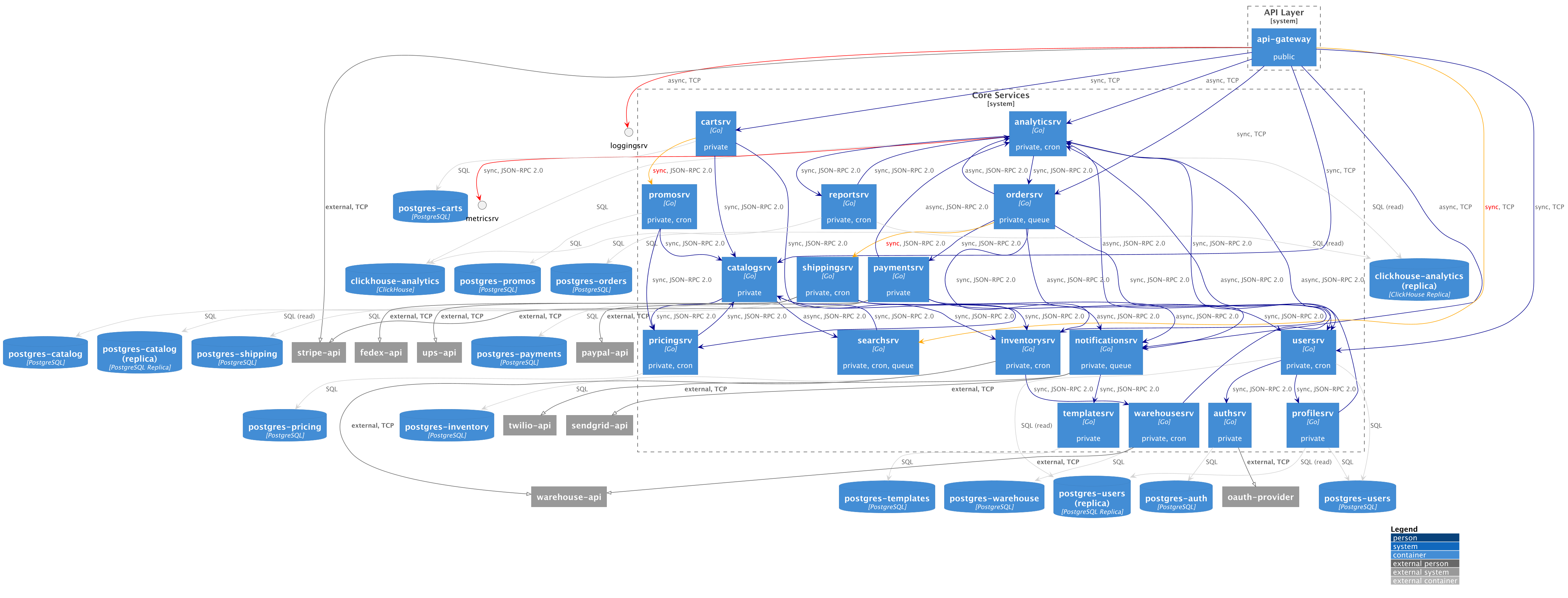
Бонус: валидация архитектуры
Одна из ключевых проблем архитектуры — расхождение «бумажного» проекта с реальностью. «Бумага» у нас — статическая метадата. Реальность — метрики HTTP-клиента и cron-задач.
Поэтому на картинке выше мы можем увидеть разницу, что хотели и что получилось, а именно:
- Связи:
- 🔴 — реальная связь есть, но в метадате не отражена.
- 🟠 — тип связи не совпадает (sync/async).
- 🔵 — подтвержденная связь (метадата + метрики).
- ⚫ — обычная связь (только из метаданных).
- ⚪ — связи с БД и очередями (обычно из конфига, можно доверять).
- Сервисы — неизвестные (не из метаданных) отображаются как малые кружки.
- Тексты — красным выделены параметры, не совпадающие с реальностью (cron, queue, sync/async).
Из этой идеи родилась команда genc4 validate, которая генерирует отчет о расхождениях.
Как попробовать?
- Если ваш стек основан на
gold-apisrv,rpcgenиappkit-клиенте — все заработает из коробки. - Если хотите просто поэкспериментировать и спроектировать, можно создать TOML-файл с топологией вручную и сгенерировать диаграмму. Сейчас попробуем :)
Спроектируем SOA-архитектуру (глава 13) для магазина с возможностью рассылки нотификаций.
topology.toml
[[Service]]
Name = "apisrv"
PublicAPI = true
PrivateAPI = true
Sync = ["ordersrv"]
Async = ["notifysrv"]
DB = ["shop"]
DBReplica = ["shop"]
[[Service]]
Name = "ordersrv"
PrivateAPI = true
Async = ["notifysrv"]
[[Service]]
Name = "notifysrv"
PublicAPI = true
PrivateAPI = true
Cron = true
BrokersrvQueue = true
Sync = ["mailtplsrv"]
External = ["mailgun", "unisender", "sms"]
DB = ["shop"]
[[Service]]
Name = "mailtplsrv"
PublicAPI = true
PrivateAPI = true
[[Service]]
Name = "statsrv"
PublicAPI = true
Sync = ["clickhouse"]
diagram.toml
Name = "diagram"
[[Boundary]]
Name = "eshop"
Suffix = "srv"
Includes = ["shop", "clickhouse" ]
[[Boundary]]
Name = "external email services"
Includes = ["mailgun", "unisender"]
[Style]
DB = ["clickhouse"]
genc4 generate: diagram.puml
Вот такой результат :). Нюансы:
- на схеме нет Person (точки входа)
- не обозначен сервис brokersrv + nats (не требуется для данной визуализации)
- нет развернутых подписей у сервисов (потому что используются 4 стандартных лейбла)
- соглашение
srvсуффикса предполагает подписи «Go» + «JSON-RPC 2.0». - фронтенд сервисы не обозначали
- в
Topology.Service.DBбаза по умолчанию Postgres.
Все эти моменты можно легко доработать под конкретные нужды.
За вайбкодингом будущее?
Прежде, чем начать что-то вайбкодить на Claude Code (а это по факту топ сейчас), необходимо:
- изучить инструмент: Claude Code in Action отлично подойдет для старта
- разобраться в лимитах: Tips for Cost-effective usage
- разобраться в подходах: например, spec driven development
- точно знать, что ты хочешь получить в итоге
- заплатить минимум 20$ за Pro план
- уметь программировать:D
Для чего подойдет
- Описание проекта, составление документации: просто сливаем весь код в Anthropic, пока он помещается в контекст, жжем лимиты и вуаля – много текста.
- Для небольших утилит, когда кода немного (потому что по факту, весь этот код каждый раз будет отправляться).
- В режиме “мне только спросить”.
- Проверить гипотезу, сделать прототип.
- Для небольших opensource проектов (код и так в интернете)
Я думаю, что кто-то в итоге должен слить все сырые данные, которые были отправлены на сервера Anthropic в виде большого торрента :),
Но честно, мне не понравилось. Задача конечно решена (не супер хорошо), но без фана программирования.
Почему мне не понравилось?
- Основное: я не программировал. У этого кода нет души.
- Код получился “неряшливый” (разработчики обычно так не пишут).
- Так как я в целом знаю, чего хочу, то через несколько итераций могу добиться удовлетворительного результата.
- Лимиты выжигаются как не в себя. Примерно за полчаса активного взаимодействия сгорают 5-ти часовые лимиты на Pro плане. А потом ты ждешь новой дозы…
- Надо слишком много читать, как бы это банально не звучало.
- За общее потраченное время (исключая написание документации) я думаю, что написал бы не медленнее (с учетом своего опыта). Потому что я точно знаю, что и как мне надо написать.
- Атрофируется навык программирования при долгом использовании (мозг не решает сложные проблемы). Передаю привет тимлидам на вечных созвонах!
- Ответственность за этот код целиком на LLM, править его нет желания.
Основная ценность в программировании для меня: донести в коде свою мысль лаконично и просто. С LLM это едва ли достижимо, потому что на каком-то этапе все равно придется объяснять (speckit, промты, документация итд).
Для тех, кто только начинает программирование: я бы рекомендовал все еще читать документацию вместо режима “объясни, как это работает”. Так мозг хотя бы немного будет напрягаться и строить новые нейронные связи.
По моим наблюдениям за окружающими родился новый термин:
chatgpt-слепота – когда ты не можешь прочитать строчку и копируешь ее в chatgpt, чтобы он объяснил, что не так
Стоит попробовать?
Конечно стоит! :)